Ente lance Ensu, un assistant conversationnel propulsé par un modèle d’IA qui tourne entièrement sur votre appareil, sans envoyer le moindre échange à des serveurs distants.
1 « J'aime »
En gros un LM Studio qui est aussi open source, sauf que lm studio sur un GPU de 8 Go de VRAM je peux mettre le modèle GLM 4.7 Flash GGUF Q4 KM, ou actuellement le GGUF Qwen 3.5 4B Q4 KM, possible de le faire tourner dans Only Office. J’attends le 9B en GGUF aussi bon qu’OpenAI OSS 120B (qui demande 233 Go et 61 Go en GGUF) alors qu’il tourne sur 8 Go de VRAM seulement. La Chine est forte dans les open sources.
Je t’arrête immédiatement mon ptit père, parce que si tu prends l’OSS 117 et que tu parcours 24 KM dans le flash code de la DGCCRF du CLUF contractuel du software, tu saurais que GWEN n’approuvera pas d’être falshé à 117KM/min séquençé en DRG67bs prime.
Alors attention à ce que tu dis ![]()
bref j’ai rien compris à ton message ![]()
4 « J'aime »
LM Studio est un soft open source pour faire tourner des modèles de LLM en local en gros un chatbox local
Ensuite quand on l’install, il propose d’installer des modèles d’IA
Mais souvent les modèles d’IA sont « gros en taille ». Pour faire simple la carte graphique basique, c’est du 8go de VRAM , on va charger le modèle dedans pour etre tres rapide. Sauf, on ne peut pas mettre un modèle de 8go, car il faut de la place pour les tokens,… Sinon ca va être déchargé sur le CPU donc lent.
Là, apparait le GGUF Q8,7,6,4,…XS, ce sont des versions « compressé » on garde la puissance d modèle original, mais on gagne en taille.
Les modèles en local qui tournent bien sûr du 8go de VRAM, on avait ministral 3 8B (mistral sorti fin 2025), Qwen 3 8B VL (peu lire les images) en version Q4 KM qui permet d’être utilisé sur les 8go de VRAM, et GLM 4.7 flash .
Mistral est déjà loin derriere, GLM est très bon.
Mais, Qwen (Alibaba ) a sorti cette semaine le modèle 3.5. Et la, c’est un gros step. et c’est open source MIT, pas plus open source que ça.
On peut faire tourner le modèle 9B Q4KM sur 8go de VRAM, et dans les bench il est l’équivalent voir meilleur que le modèle qu’open AI a sorti en 2025 OSS 120B qui lui demande un GPU avec au moins 70go de VRAM (version GGUF) autant dire des milliers d’euros de matos pour le faire tourner.
Open AI reste toujours meilleur pour des projet de code complexe. Mais bon GPU 8go, vs 70 go
Mais en analyse d’image et graphique, QWEN 3.5 est loin devant
et le Qwen 3.5 4B Q4, on peut facilement l’utiliser dans onlyoffice en étant large sur les 8go de VRAM, car fait 2.78go, donc de la place pour plein de tokens et windows et onlyoffice sur le GPU, sachant que pour knownledge et stem, c’est très proche du 9B, tout comme la compréhension de 201 langues et très bon en traductions,…
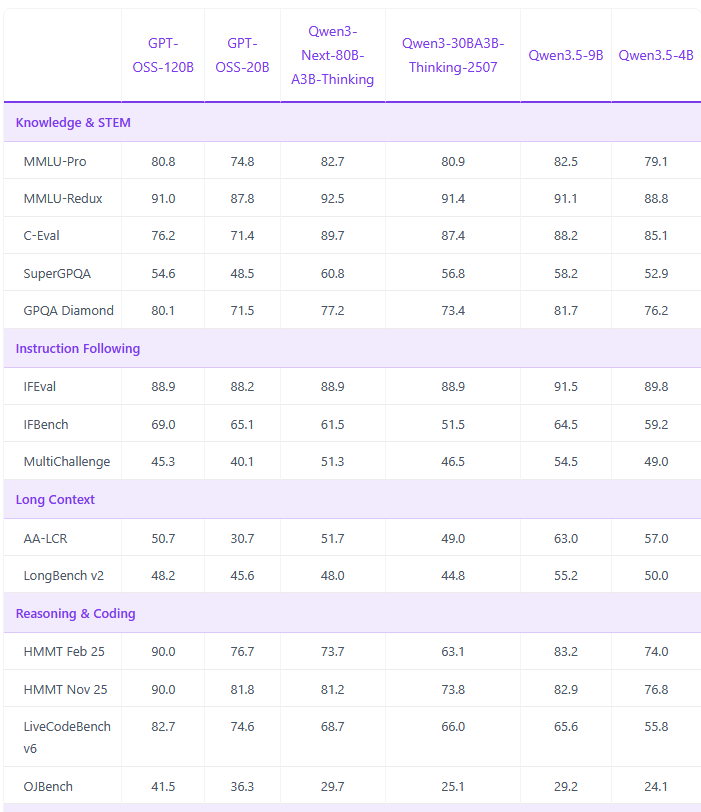
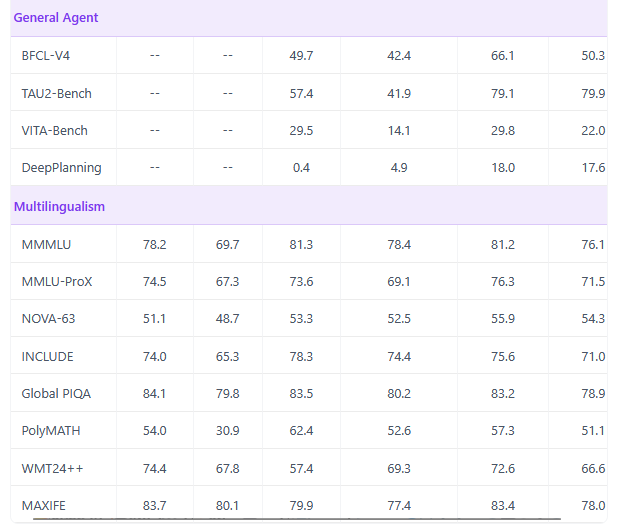
Les bench
Résumé
MMLU / MMLU-Pro (La culture générale)
C’est le test de référence mondial. Il pose des milliers de questions à choix multiples sur 57 sujets différents : histoire, droit, médecine, physique, éthique, etc.
- MMLU-Pro (présent dans ta liste) est la version « difficile » : au lieu de 4 choix de réponses, il y en a 10, ce qui empêche l’IA de deviner la réponse au hasard.
2. GPQA (Le niveau Doctorat)
GPQA signifie Graduate-Level Google-Proof Q&A. Ce sont des questions de biologie, physique et chimie tellement complexes qu’elles sont « Google-proof » (difficiles à trouver avec une simple recherche web).
- Elles sont rédigées par des experts (Ph.D.) et même d’autres experts du même domaine ont du mal à y répondre sans aide.
- Le score Diamond montre la capacité du modèle à raisonner sur des concepts scientifiques pointus.
3. C-Eval (Le savoir académique)
C’est un benchmark similaire au MMLU mais centré sur le système éducatif chinois. Il teste les connaissances en sciences dures et sociales avec une grande exigence sur la précision des faits.


3 « J'aime »
Et tout est dispo sur hugging face
Pour les images c est comfui UI, et les modèles pour du 8go de vram c est Z-image turbo Q4, pareille Alibaba, permet de créer ou éditer des images le tout open source très bon en qualité, c est quelques seconde pour faire une image. Pas de censure il connait politiques célébrités,…
Il y a aussi flux klein , sympas aussi
Tout est sur ![]() hugging face
hugging face
A lire l’article, j’ai du mal à saisir l’intérêt de Ente. Je suis moi aussi un utlisateur de Lm studio ( au travers duquel j’utilise une version compressée de Mistral 14B, avec 16 giga de Vram). C’est parfait en local pour de l’écriture créative, l’interprétation d’image ou l’assistance en programation ou d’autres sujets divers. Pour les images, j’ai aussi Invoke, qui permet d’utiliser Z image ou Flux. Toutes ces solutions sont locales, gratuites et open source, et parfatement adaptées à un usage individuel.